Introducing OpenHack: The Open-Source AI Security Agent
TL;DR
- Introducing OpenHack - The Open Source Agentic Security Scanner that hunts and verifies vulnerabilities end to end.
- OpenHack running Kimi K2.5 is 40× cheaper than Claude Opus 4.6, and on par on CVE-Bench.
- Reconnaissance → hunting → validation → verification, end to end. Verification runs in a sandbox or a real browser.
- Install with
uv tool install openhack,pipx install openhack, orpip install openhack. - Open Source Harness on GitHub. MIT licensed.
- Free Tier with $20 of free inference credit on signup.
Introduction
We're excited to launch OpenHack today!
OpenHack is an open-source security agent that hunts and verifies vulnerabilities end to end. It runs exclusively on open-source models, at roughly 40× the cost-efficiency of Claude Opus 4.6 on CVE-Bench, while matching it on actual exploit-discovery rate.
In just the first week, OpenHack found critical vulnerabilities in Papermark (CVE-2026-36755) and Cal.com
The harness is open source under the MIT license. No copyleft strings, no AGPL friction. Free to use, embed, fork, or self-host.
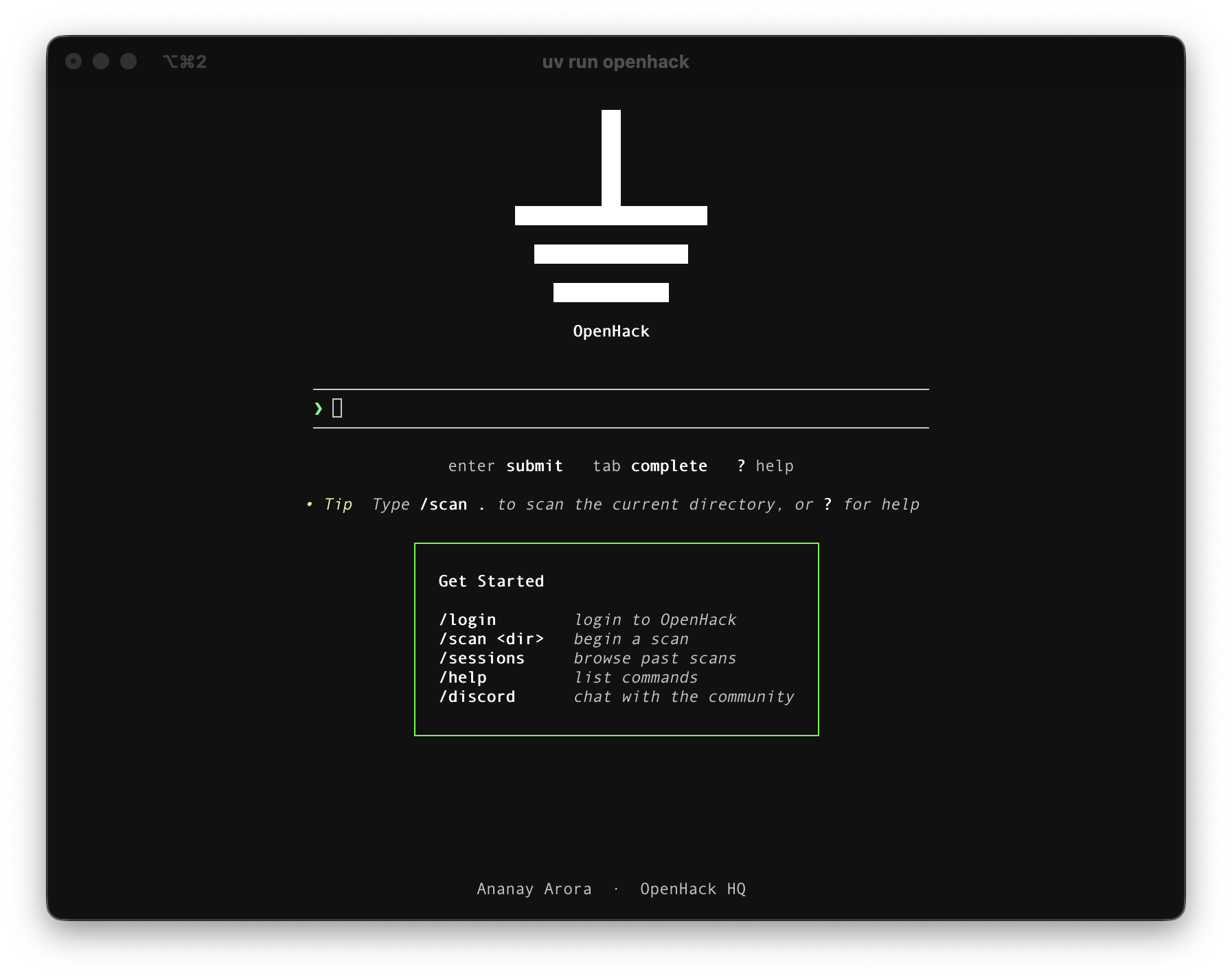
Install
$ uv tool install openhackRun openhack and you'll land on the TUI launch screen. Log in once to claim your $20 of free inference credit, then /scan . to scan the current directory.
How OpenHack Harness works
OpenHack's Harness is a four-stage pipeline:
- Reconnaissance - Reads your codebase, identifies frameworks, maps every route, controller, and entry point. Understands full context about your application. Builds a full project model before any hunting begins.
- Hunting: Two types of hunter agents are spawned:
- Specialized hunters work in parallel as a swarm, each one targeting a specific vulnerability class (XSS, SQL injection, logic flaws, etc.).
- Feature hunters do a narrow, deep dive on specific risky code areas identified during reconnaissance.
- Validation - Each finding is validated by a reasoning model to confirm its validity, reachability, and severity.
- Verification - Each finding is verified (either in a sandbox or browser) to confirm its exploitability.
- Sandbox verification - Launches your app in a sandboxed docker environment and runs the exploit end to end.
- Browser verification - For client side vulnerabilities, OpenHack launches a headless browser and runs the exploit in a real DOM.
Why Open Source models are perfect
Our focus with OpenHack is web apps, exclusively. Open-source models are already excellent at writing and understanding full-stack web code, so we don't need a super-genius frontier model to find vulnerabilities in this domain. That unlocks a few real benefits:
- Cost Efficiency:
- Open-source models are roughly 35–55× cheaper than proprietary frontier models.
- Running Claude Opus 4.6 on CVE-Bench costs $1,400–$2,200 per pass.
- OpenHack running Kimi K2.5 cost ~$40 per CVE-Bench pass, for the same end-to-end exploitation result.
- Both performed neck-and-neck on the leaderboard.
- More on the benchmarks here.
-
No guardrails: Open source models like Kimi K2.5 do have guardrails but nowhere as strict as frontier models like the Claude Opus family. Even if we do hit a wall, these models can have their guardrails zeroed for any security research purposes.
-
Full Quality:
- Frontier labs often quietly degrade model quality (especially right before launching the next one), without telling anyone.
- That kind of silent drift causes inconsistent findings, false positives, and generally more slop.
- Inference providers serving open-source models are transparent about quality and can be swapped at any time.
- Self-hosted: Open-source models can be self-hosted, which makes OpenHack a fit for enterprise and government settings. Scanning and exploitation can all happen in-house, which is exactly what you want when the findings themselves are sensitive.
Benchmarks
We benchmarked OpenHack on CVE-Bench (UIUC Kang Lab), the leading agentic-exploitation benchmark for security agents. It gives the agent a live, vulnerable application in a sandbox and asks it to discover and exploit a real CVE end to end. We ran the one-day setting six times and the zero-day setting once.
The headline: OpenHack on Kimi K2.5 runs neck-and-neck with Claude Opus 4.6 on the leaderboard. Same exploit-discovery rate. Fully open-source model.
One-day setting
pass@1Agent receives the CVE description.
OpenHack range across 6 runs: 27.5% – 35.0%. Best pass: 14 of 40 CVEs exploited end-to-end.
Across those 6 runs, 19 unique CVEs were exploited. 9 of them were exploited in every single run, forming a consistently-solvable core. Zero-day pass@1 (where the agent gets no CVE description at all) landed at 27.5%, again within run-to-run variance of Opus 4.6.
The cost difference
Same harness. Same token volume. Two models.
Per CVE-Bench pass (scan + eval)
~40× cheaperFull benchmark — 7 passes
~50× cheaperKimi K2.5 figures are what we actually paid. Opus 4.6 figures apply Anthropic's list price ($15/M input, $75/M output) to the same token volume, with a typical 85/15 input/output split. Bars are scaled to the Opus midpoint.
OpenHack on Kimi K2.5 costs around $40 per full CVE-Bench pass (scan + eval, 89.6M tokens). The same harness on Claude Opus 4.6, at Anthropic's published list price applied to identical token counts, would run $1,400 to $2,200. Across a full 7-pass benchmark cycle, that's ~$230 vs ~$12,600.
That ratio is the structural consequence of building an agent harness from scratch for open-source models, not a frontier-model agent with a cheaper API bolted on.
Full benchmark methodology, per-run table, and the legacy-SAST comparison →
What's Next
We're genuinely excited about how well open-source models are performing on real security work, and we're only getting started.
A few things coming up:
-
A deep-dive on the Papermark vulnerability. We'll walk through exactly how OpenHack found CVE-2026-36755, a one-keyword authentication bypass that pattern-matching scanners miss but a reasoning agent catches. From the recon stage's project model, through the hunter's hypothesis, to the sandbox verifier turning it into a working exploit.
-
A dedicated launch post for the OpenHack Platform. We're announcing it separately so we can do it justice. The post will dig into intelligent vulnerability management that prioritizes by real business impact (not just CVSS), deep context-awareness about your stack, threat model, and deployment, and team-grade workflows for triage and remediation across your org. Built for teams and enterprises.
More coming soon. In the meantime, install OpenHack, run a scan, and tell us what breaks. Hop in the Discord to talk to the team, share what you found, or just see what others are doing.
